Implementation of FH Project
Any new project that comes is meant for FirstHive only – irrespective of the customer and the scope that has been called out during the closing of sale. Anything in the module cannot exist without FirstHive, everything has to start with FH as a platform.
The project enrollment starts with:
- Planning Phase – Config. Note, which explains what has to be included in the project and vice-versa.
- Account Setup – Setting up a new account for the customer.
High-level Steps
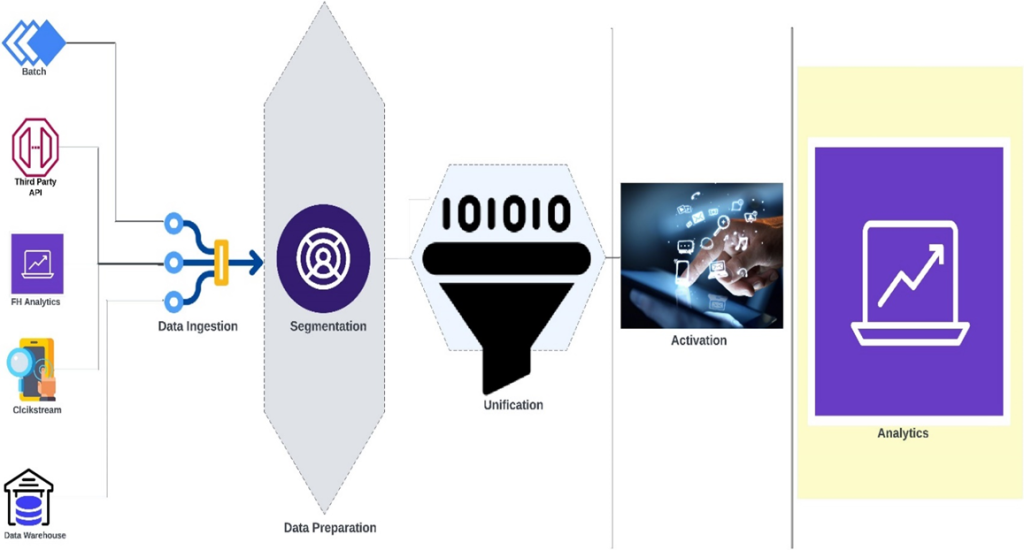
The actual implementation of a project is followed by the below steps:
Step 1: Data Ingestion
Step 2: Data Preparation
Step 3: Unification
Step 4: Activation
Step 5: Analytics
Data Ingestion
Data Ingestion is a major data handling approach that transfers data from one or more external data sources into an application data store or specialized storage repository. By using this process, you can ingest data from various sources which, and this can be Data-in or Data-out. The source data is brought in as is, meaning that fields and their data types are imported without transformation.
As data may be in multiple different forms and come from hundreds of sources, it is transformed into a uniform format.
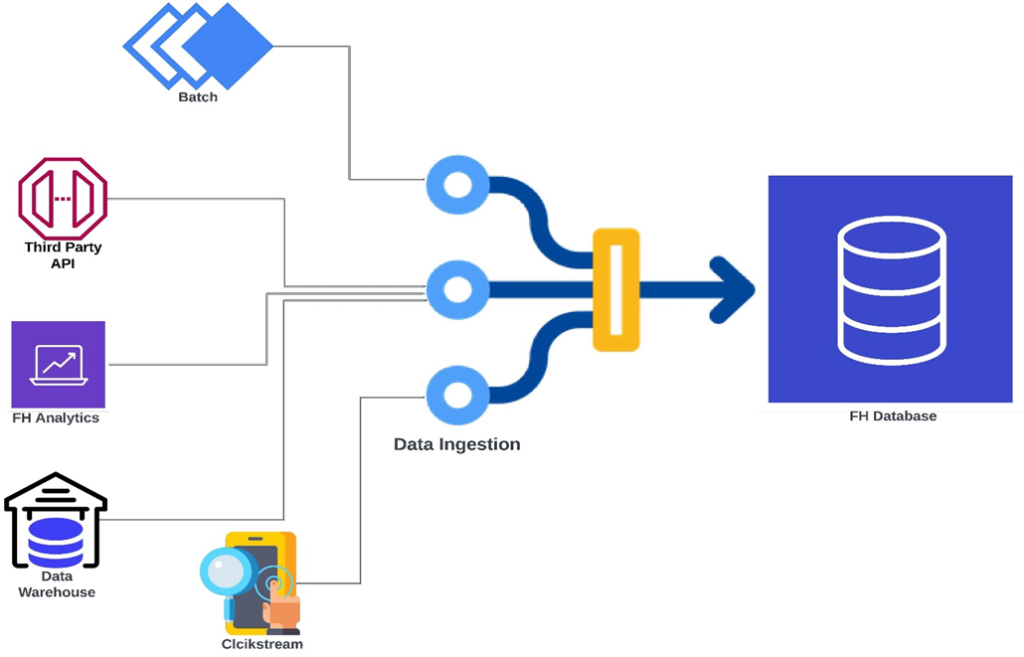
These are following sources through which FirstHive gets the data-in to the system:
- Batch-based: This is one type of data FirstHive gets in. In batch-based data ingestion, the ingestion layer collects data from sources incrementally and sends batches to the system where the data is to be used or stored. The ingestion layer may collect data based on simple schedules, trigger events, or any other logical ordering. Batch-based ingestion is useful when you need to collect specific data points on a daily basis or simply don’t need data for real-time decision-making. This approach is good for applications that don’t require real-time data. It is typically less expensive.
To get batch data in, FirstHive uses StreamSets, run Cron Job to fetch from SFTP, run PHP and Python scripts. The data FH receives can be normalize data and de-normalize data. For example, the data FH receives from Franklin Templeton (FT) is in normalize form and the data it receives from Royalsundaram (RS) is in de-normalize form.
|
FirstHive gets the real-time data from Batch-based process, Third-party API, and Clickstream. |
- Third-party API: Customers use different kinds of tool and they want FirstHive to pull the data from there. In addition to this, they also open up their API endpoint or push the data through webhook, and FirstHive gets the data from there.
|
FirstHive is using the customers API in both the cases, not the FH API. |
- FH Analytics: This is basically the transfer of data that happens between two APIs. Clients open their API and FirstHive opens its API to send the data. You can take FH WhatsApp API as an example. In FH API, either the data comes in or FH is ingesting the data by itself.
- Clickstream Data: Users find their way to customers site/app and perform various actions. Visiting a page, clicking a button, submitting information, and purchasing a product are examples of such activities. But these user data points aren’t helpful unless you create a process to log them.
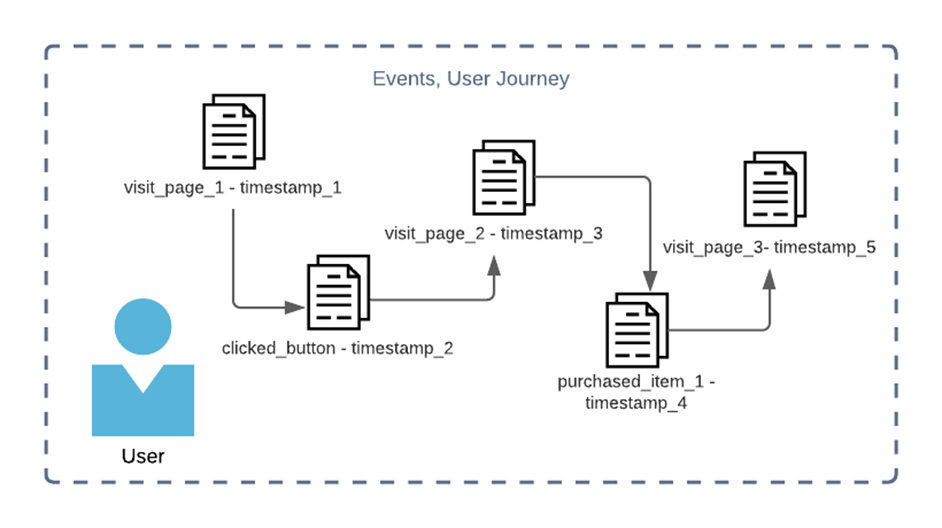
Using Segment as an example, your website is added as a data source, and segment then provides the required JavaScript code to start tracking user events and sending them to segment.
- Data Warehouse Application/Data Lake: This is a new thing FirstHive is implementing now as a POC. However, 90% of data comes from the first four.
There is nothing beyond these five. This is the universe, how the data comes into FirstHive and goes out. And, how the data comes in is completely PS team’s call. |
Stitch Streamlines Data Ingestion
A sound data strategy is responsive, adaptable, performant, compliant, and future-ready, and starts with good inputs. Creating an ETL platform from scratch would require writing web requests, API calls, SQL or NoSQL queries, formatting procedures, transformation logic, database controls, and more. Nobody wants to do that, because DIY ETL takes developers away from user-facing products and puts the accuracy, availability, and consistency of the analytics environment at risk.
With Stitch, you can bring data from all of your sources to cloud data warehouse destinations where you can use it for business intelligence and data analytics. Because Stitch is a fully managed ELT solution, you can move data from ingestion to insight in minutes, not weeks.
Things to Take Care During the Process
There are few things that need to be taken care by the team during the process, they are as follows:
- When the data comes to staging you must keep an eye on them. You need to have a certain mechanism to reconcile the data for that you must keep the copy of data in staging.
- Data ingestion must be into FirstHive only.
- Every time you pull the data into staging and you do not pull the data into FirstHive, then it is against the policy.
- The primary vector for the team is to build events. There is a particular model, how the data would come into FH and the team needs to follow the same.
- You must transform the data into FirstHive’s format which is called normalize.
Data Preparation
Data preparation is the process of preparing raw data so that it is suitable for the downstream systems (a downstream system is a system that receives data from the Collaboration Server system). Data flows through organizations from multiple sources like, from smartphones to computer systems in both structured and unstructured format (images, documents, geospatial data, and more).
What FH does is, enable fields for segmentation and others. FirstHive is releasing the data by ensuring the data in such a format/model which is fit for those downstream system. The customer is using FH services to send the campaign out, which could be very well from Adobe or Salesforce.
Unification
There are two types of unification in high-level:
- Deterministic Only
- Default
Deterministic Only
All the customers (FT, HDFC, RS, etc.,) come under this category from whom FH takes the license fee.
Use Case
- Use Case 1 (Basic Deterministic): Only Mobile Number – as long as you have the mobile number, you do not need anything else. You take the same number from different sources and unify it. For example, Pidilite.
- Use Case 2 (Hierarchal Deterministic): Use mobile number but in a particular order. First unify on the basis of battery_id or use the chassis number, followed by a mobile number and email id. There is a certain hierarchy that you need to follow. This means, do not start with the mobile number, see if you are getting the battery_id from two sources. You can go ahead and do not need to check for anything else.
Both basic and hierarchical are a part of deterministic. |
Default
The deterministic layer which is running, on top of that the probabilistic graph created by the system in the backend figures out the likenesses or similarities between the entire customer data (who is relate to who and whom related to whom), whereas each cluster figures out – what percentage and how much somebody will match (applying the standard deviation logic here).
The output is – you get deterministic identified customer list and from the probabilistic piece, you get the probabilistic graph of the likenesses. Likeness will translate into HHIDs (Household ID) or low probability matches, whereas the deterministic and high probability matches will give you the GUID (Global ID) and FHID (FirstHive ID).
Activation
In this process, you find all the integrated channels or those need to be integrated. Be it Email, SMS, Mobile App, IVR, CC, Messenger, Browser Notification, WhatsApp, etc., any channel integrated as a part of config. note will be here. You just need to make sure that all the data available are in a position/format which can be used under activation, this means the build out segments are required.
All the data which are relevant will be there in FH. If you are running a campaign should be able to capture conversions against that particular id, when visitors coming to the website and performing activities that data is coming in.
The data may not be wanted by the customer, but at FirstHive there is no other way we implement. |
Analytics
You get the unified data which is in such a state/format that you can run a campaign. You start executing the campaign and there are default analytics that come here – all of them combined to become a single piece and available here. There are 15 to 18 reports which are available by default within FirstHive. On top of this, you have the entire solution module that comes into play. This is how the FH CDP works.
These five steps comprise every deployment you see across FirstHive.
In Kotak the data is coming into FH. FirstHive is a single product company that only implement FH CDP, there is no concept of non-CDP customer. The scope may vary and based on the scope; the license varies. New modules may come up in near future, but our product is constant. |